
1- Vue d’ensemble
Système de maintenance prédictive de bout-en-bout pour moteurs d’avions. Prédiction du RUL sur le dataset NASA CMAPSS avec Random Forest, XGBoost, sklearn Pipelines & MLflow.
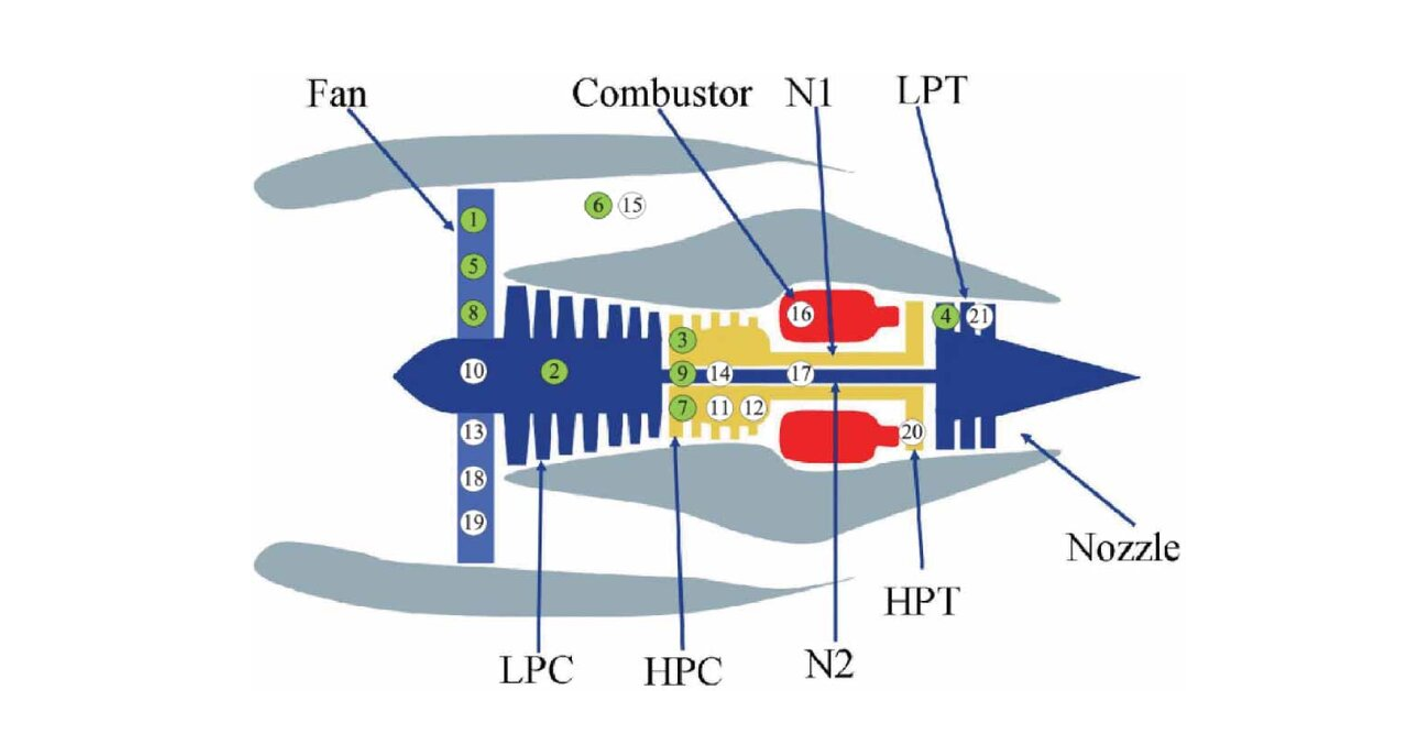
2- Contexte & Motivations
Problématique
La maintenance aéronautique repose sur deux modes : la maintenance programmée (remplacement systématique après N heures de vol, quelle que soit l’état du composant) et la maintenance corrective (réparation après panne). La première génère des coûts inutiles en remplaçant des pièces encore saines tandis que la seconde expose à des défaillances en vol potentiellement catastrophiques. La maintenance prédictive est une alternative particulièrement intéressante : les interventions sont planifiées au moment précis où un composant approche de sa fin de vie.
L’enjeu économique est considérable puisqu’un un retrait non planifié d’un moteur peut rapidement coûter des centaines de milliers d’euros en frais d’immobilisation (AOG — Aircraft on Ground) et pièces d’urgence, sans prendre en considération les conséquences en termes de sécurité.
Défis techniques
Un turboréacteur se dégrade progressivement au fil de milliers de cycles opérationnels. Les défis sont les suivants :
- Extraire un signal de dégradation propre à partir de données temporelles bruitées et de haute dimension
- Prédire le nombre de cycles restants avec une précision suffisante pour planifier la maintenance à l’avance
- Généraliser à des moteurs jamais vus lors de l’entraînement
Pour cela, on introduit le RUL (Remaining Useful Life), c’est-à-dire le nombre de cycles restants avant la panne. Sa prédiction précise est l’enjeu central des problèmes de maintenance prédictive, avec des applications dans de nombreux domaines industriels.
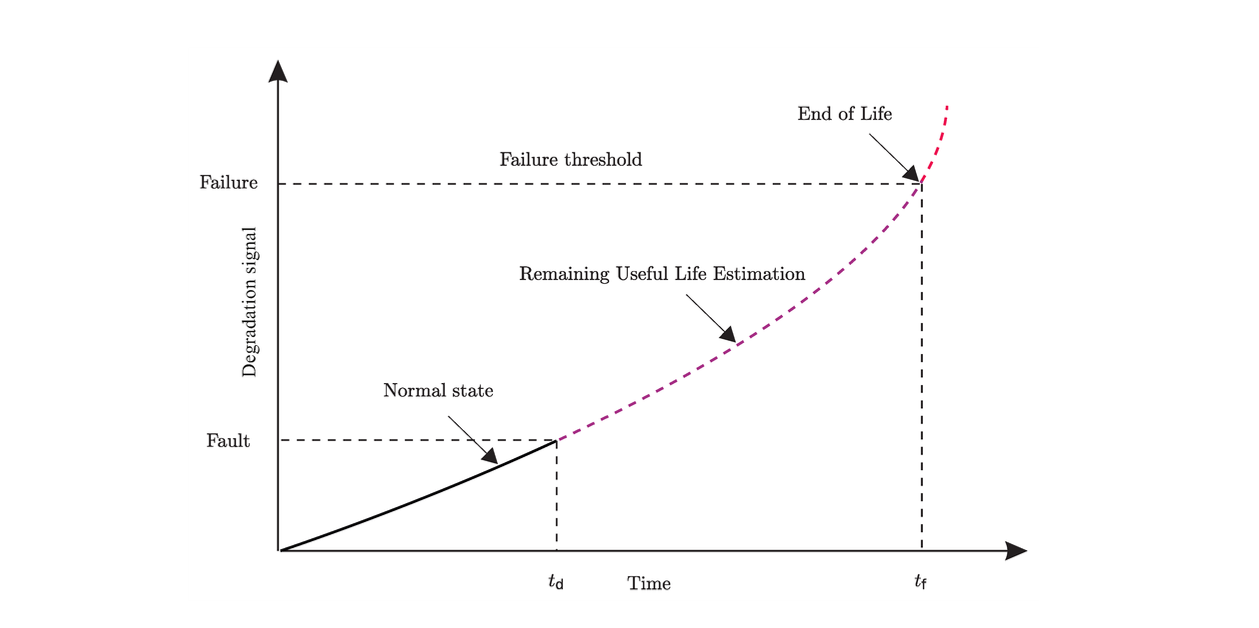
Objectif & méthodologie
Construire un pipeline ML complet, des données brutes jusqu’à l’analyse de risque opérationnel, en s’appuyant sur le dataset de référence NASA CMAPSS, et en validant les résultats sur le dataset officiel de la NASA ainsi que le système de scorage de la compétition PHM 2008.
3- Dataset
CMAPSS (Commercial Modular Aero-Propulsion System Simulation) a été publié par le NASA Ames Research Center pour la compétition PHM 2008 et reste le benchmark de référence pour la prédiction de RUL. Il simule la dégradation progressive du compresseur haute pression d’un moteur jusqu’à la panne.
Ce projet se concentre sur le dataset FD001 : 100 moteurs d’entraînement et 100 moteurs de test, tous opérant sous une condition unique avec un seul mode de défaillance.
Chaque ligne du dataset représente un moteur à un cycle opérationnel donné, avec 21 relevés de capteurs et 3 réglages opérationnels :
| # | Symbole | Description | Unité |
|---|---|---|---|
| Engine | |||
| Cycle | |||
| Setting 1 | Altitude | ft | |
| Setting 2 | Nombre de Mach | M | |
| Setting 3 | TRA (Throttle-Resolver Angle) | deg | |
| Sensor 1 | T2 | Température totale à l’entrée du ventilateur | °R |
| Sensor 2 | T24 | Température totale en sortie LPC | °R |
| Sensor 3 | T30 | Température totale en sortie HPC | °R |
| Sensor 4 | T50 | Température totale en sortie LPT | °R |
| Sensor 5 | P2 | Pression à l’entrée du ventilateur | psia |
| Sensor 6 | P15 | Pression totale dans le bypass | psia |
| Sensor 7 | P30 | Pression totale en sortie HPC | psia |
| Sensor 8 | Nf | Vitesse physique du ventilateur | rpm |
| Sensor 9 | Nc | Vitesse physique du cœur | rpm |
| Sensor 10 | epr | Rapport de pression moteur | – |
| Sensor 11 | Ps30 | Pression statique en sortie HPC | psia |
| Sensor 12 | phi | Rapport débit carburant / Ps30 | pps/psi |
| Sensor 13 | NRf | Vitesse ventilateur corrigée | rpm |
| Sensor 14 | NRc | Vitesse cœur corrigée | rpm |
| Sensor 15 | BPR | Taux de dilution | – |
| Sensor 16 | farB | Rapport air-carburant brûleur | – |
| Sensor 17 | htBleed | Enthalpie de prélèvement | – |
| Sensor 18 | Nf_dmd | Vitesse ventilateur demandée | rpm |
| Sensor 19 | PCNfR_dmd | Vitesse ventilateur corrigée demandée | rpm |
| Sensor 20 | W31 | Prélèvement HPT | lbm/s |
| Sensor 21 | W32 | Prélèvement LPT | lbm/s |
- LPC/HPC : compresseur basse/haute pression — LPT/HPT : turbine basse/haute pression
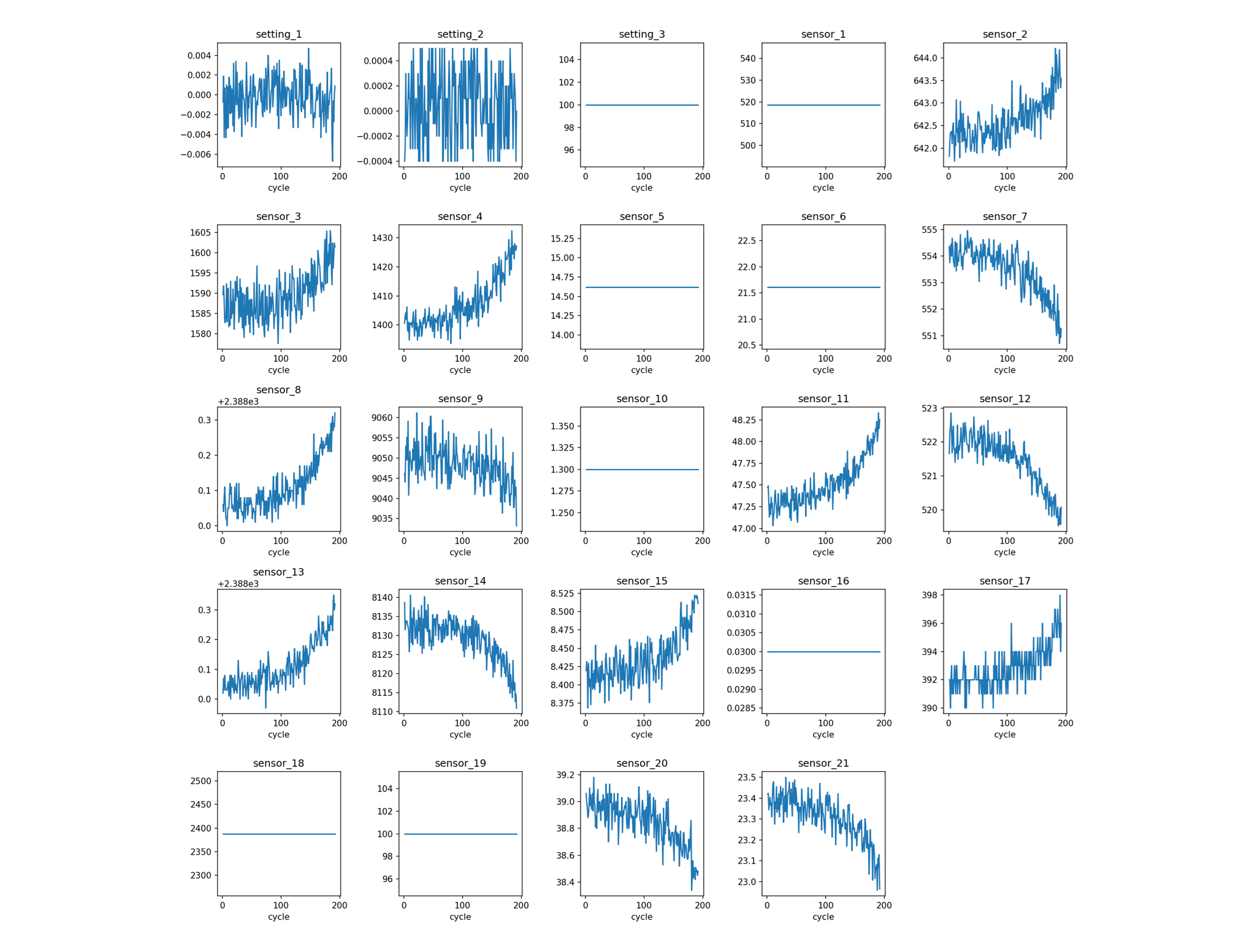
Certains capteurs affichent une dégradation progressive claire, tandis que d’autres sont constants ou purement bruités :
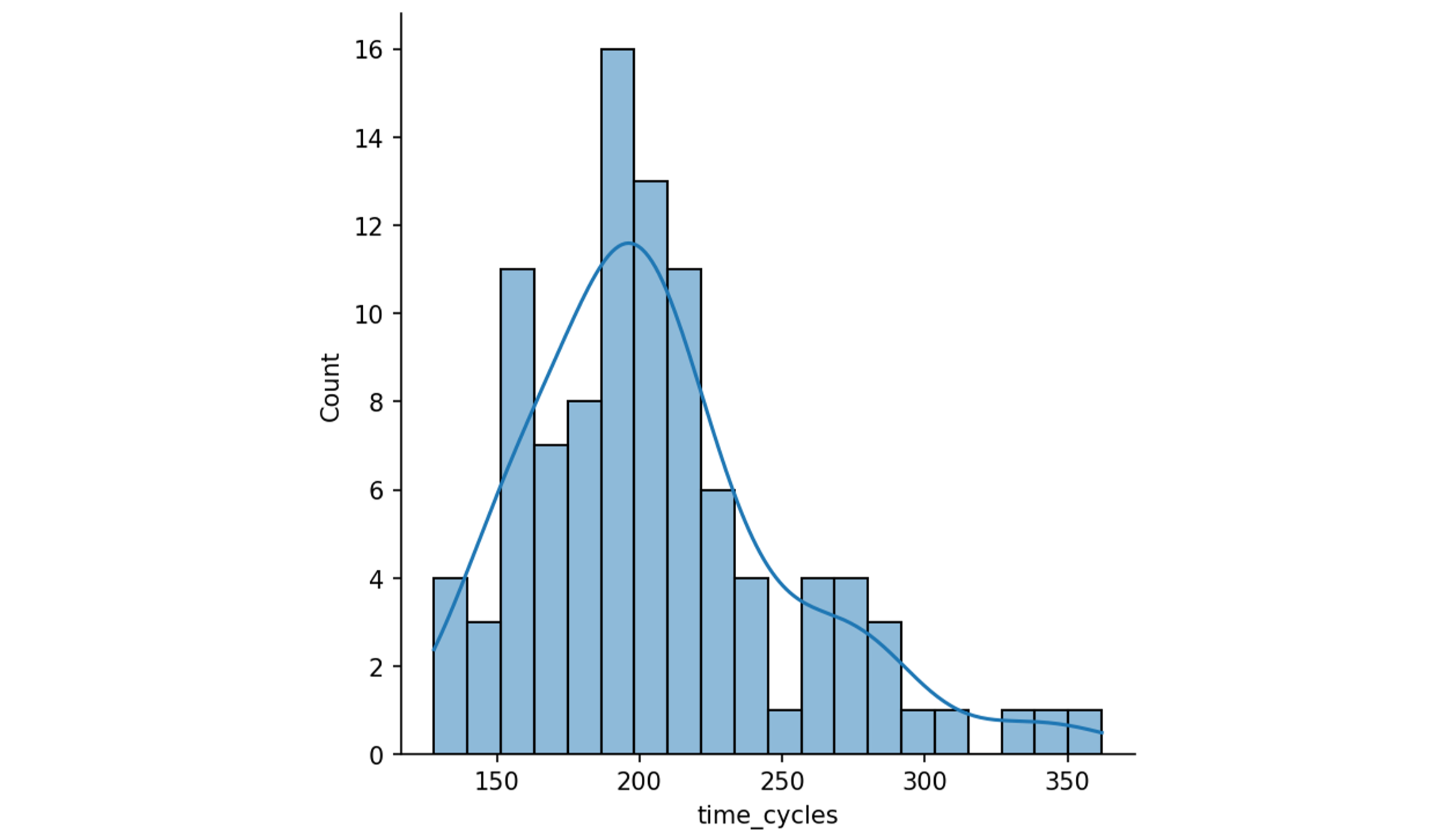
La durée de vie des moteurs dans le dataset varie de 128 à 362 cycles :
4- Feature Engineering
Les relevés bruts des capteurs nécessitent plusieurs transformations avant d’être exploitables par un modèle. Quatre opérations sont appliquées dans l’ordre suivant :
Calcul et clipping du RUL
Pour chaque moteur on a : $$\text{RUL}(t) = \text{max\_cycles} - t$$
Un clipping à 120 cycles est appliqué. Au-delà de cette valeur, le moteur est en bonne état et prédire un RUL précis n’a pas de pertinence opérationnelle. En effet, la maintenance ne se planifie pas 300 cycles à l’avance. Ce clipping est standard dans la littérature CMAPSS et concentre l’apprentissage sur la zone où la prédiction importe réellement.
Suppression des features à faible variance
Les features dont la variance est inférieure à $10^{-5}$ sont constantes (ou quasi-constantes) et ne donnent aucune information utile.
Features temporelles
La dégradation mécanique est un processus lent. Pour capturer les tendances sous-jacentes tout en lissant le bruit, on calcule la moyenne mobile et l’écart-type mobile sur 5 cycles, ainsi que la différence instantanée pour détecter les changements rapides. Pour chaque capteur conservé, on obtient :
rolling_mean_5— tendance localerolling_std_5— variabilité localediff_1(différence instantanée) — vitesse de variation
Filtrage par corrélation
Les features avec $|\text{corr}(\text{RUL})| \leq 0.1$ sont supprimées. Le jeu de features final contient 28 features.
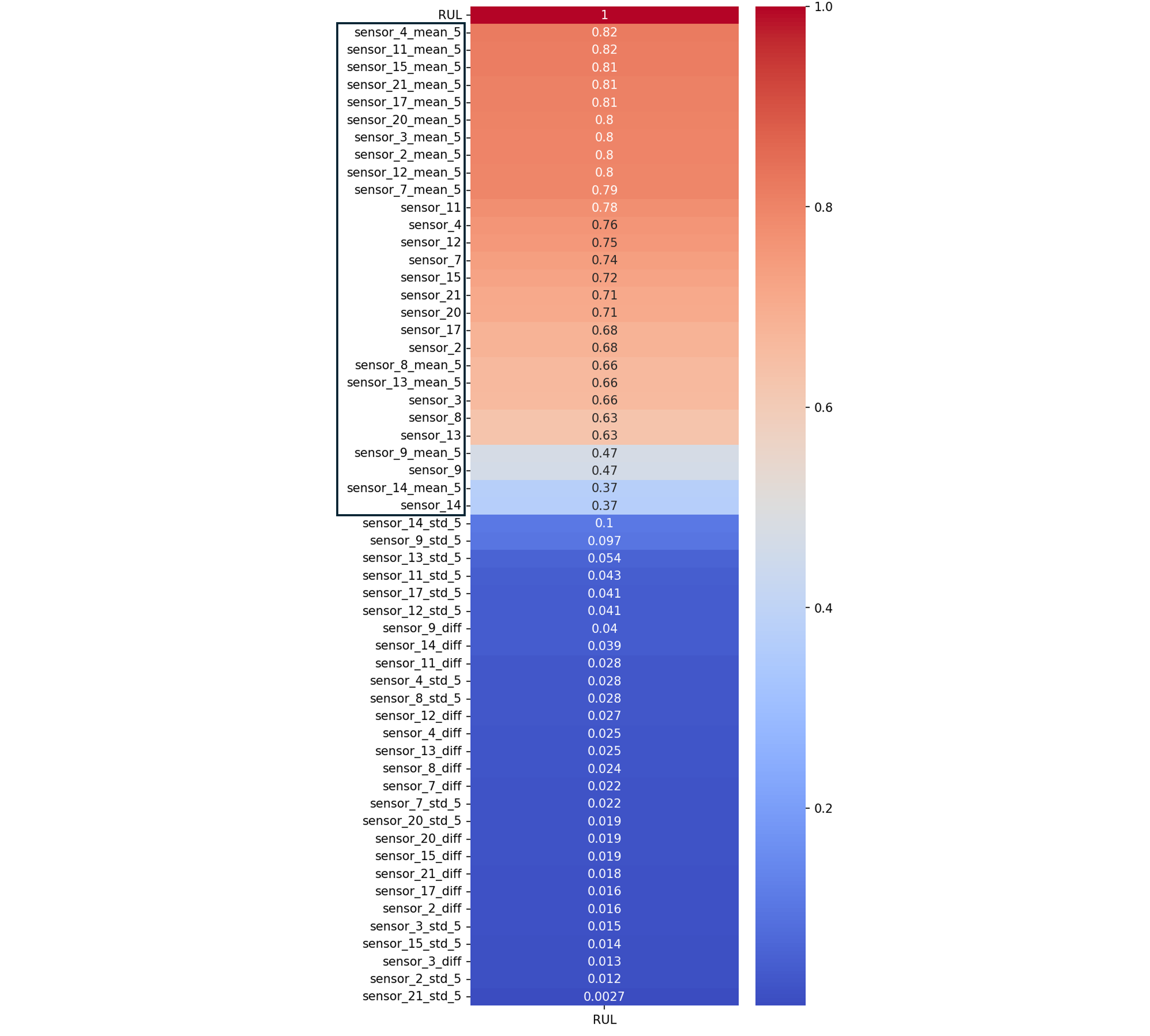
5- Sélection & Entraînement des modèles
Le split est effectué par moteur (et non aléatoirement sur les lignes) pour éviter toute fuite de données : un même moteur ne peut pas apparaître à la fois dans le train et le test. On implémente ensuite les modèles suivant une progression classique, du plus simple au plus complexe.
Baseline
Le modèle baseline prédit systématiquement la moyenne du RUL du jeu d’entraînement pour chaque observation. C’est le benchmark minimum à dépasser.
Linear Regression
Premier modèle supervisé, sensible à l’échelle des features. On applique un StandardScaler sur les donées entrantes, pour évaluer si le signal de dégradation est exploitable de manière linéaire.
Random Forest
Le Random Forest est un modèle d’ensemble learning composé d’arbres de décision. Chaque arbre est entraîné sur un sous-ensemble aléatoire des données et des features (bagging). La prédiction finale est la moyenne des prédictions de tous les arbres. Ce double processus réduit la variance (overfitting) tout en gardant chaque arbre individuellement interprétable.
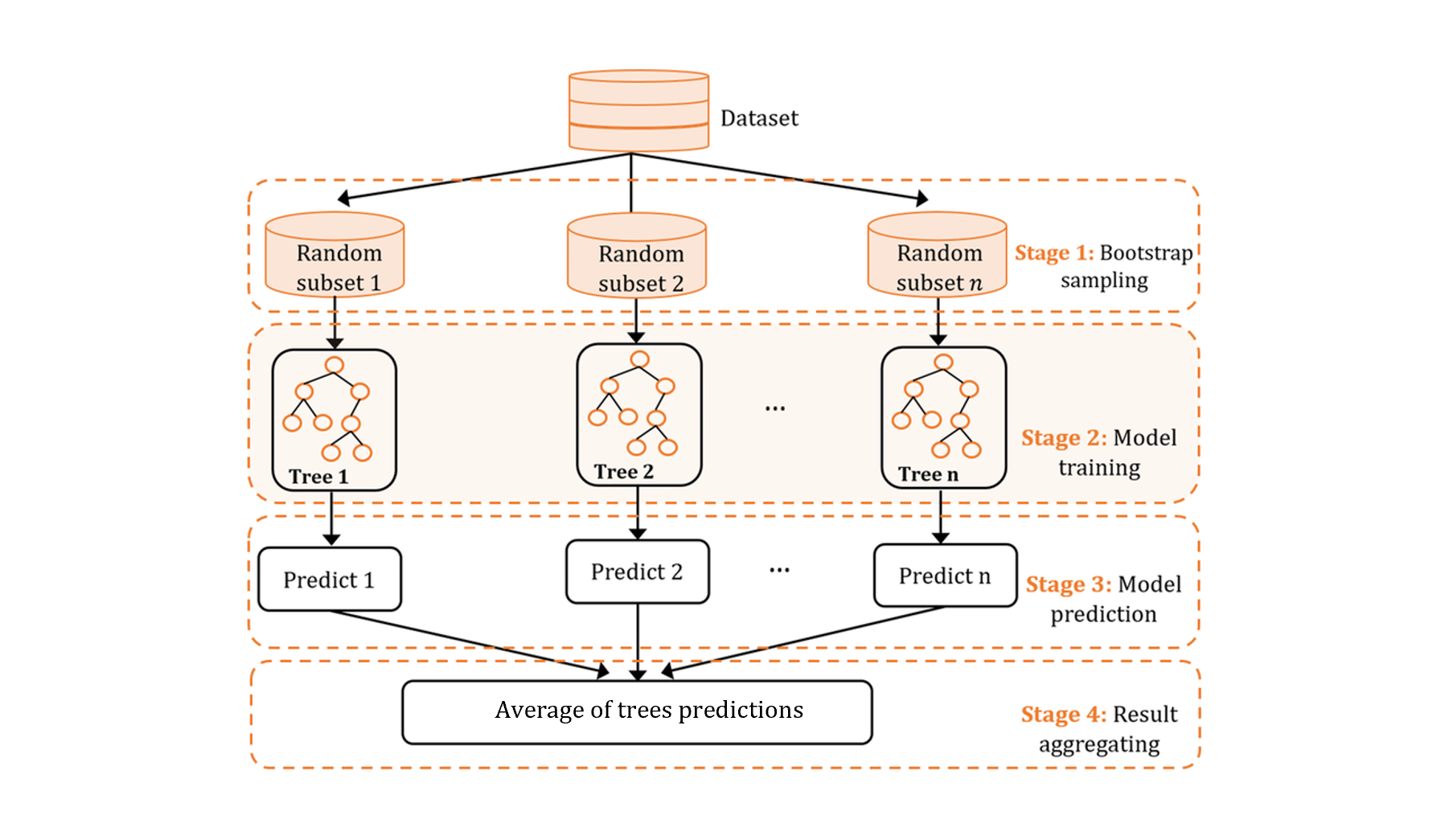
Avant le tuning, un Random Forest vanilla est entraîné avec des paramètres par défaut, et les 15 features les plus importantes sont sélectionnées. L’importance des features est mesurée par la réduction moyenne d’impureté (Gini) sur l’ensemble des splits. Réduire la dimension à ce stade limite l’overfitting et accélère le temps d’entraînement.
XGBoost
Contrairement au Random Forest qui construit les arbres en parallèle, XGBoost les construit séquentiellement, chaque arbre corrigeant les erreurs résiduelles du précédent. Cela le rend plus efficace en données, mais aussi plus sensible à l’overfitting sans régularisation.
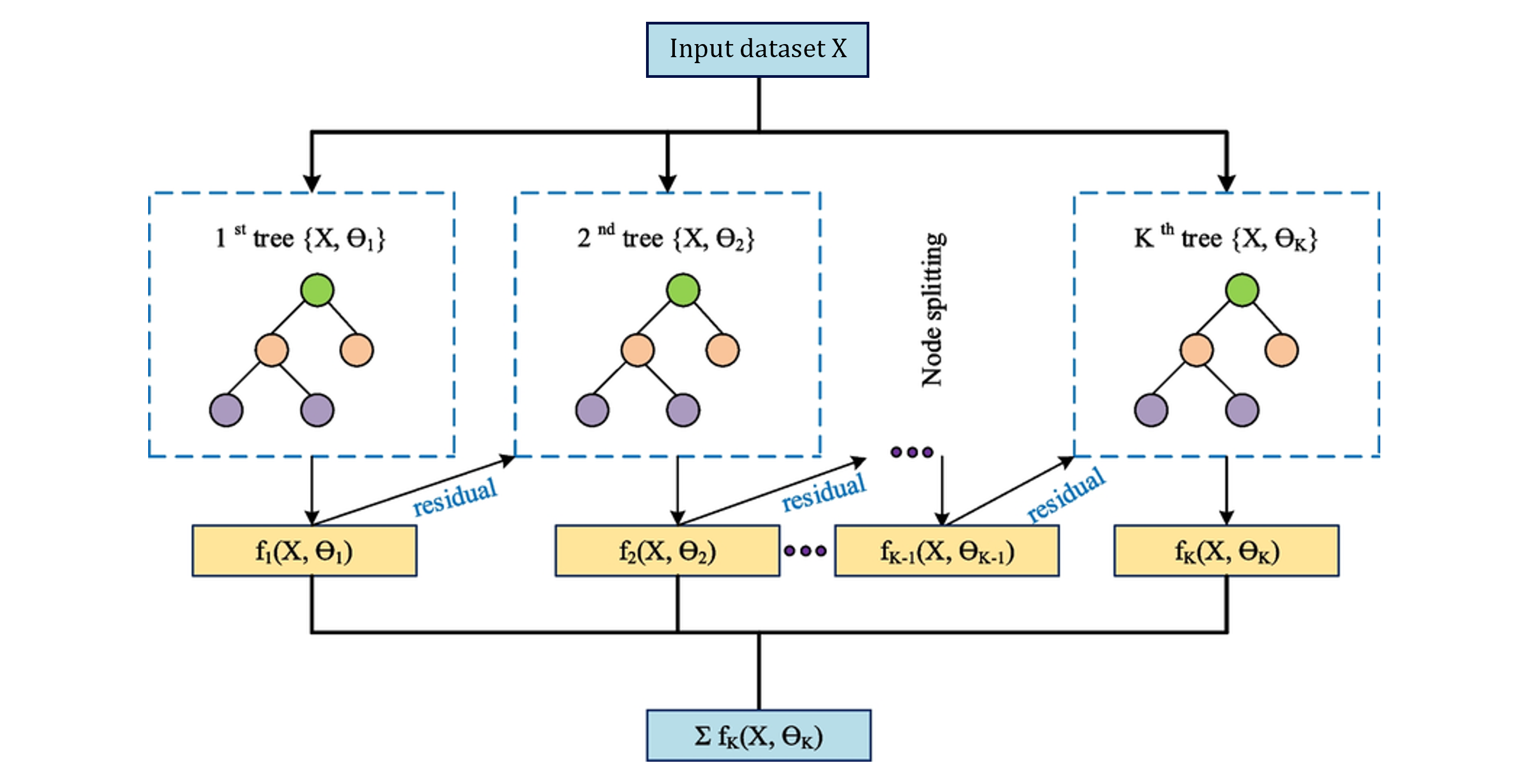
Même démarche que pour le Random Forest : un XGBoost vanilla est d’abord entraîné, puis les 15 features les plus importantes sont sélectionnées. XGBoost mesure l’importance en calculant le gain (amélioration de la loss à chaque split), ce qui produit un classement différent du Random Forest.
Hyperparameter tuning (Random Forest et XGBoost)
GridSearchCV() sur les principaux hyperparamètres :
| Modèle | Hyperparamètres |
|---|---|
| Random Forest | n_estimators ∈ {100, 200, 300} |
max_depth ∈ {None, 10, 20} | |
min_samples_leaf ∈ {1, 3, 5} | |
| XGBoost | n_estimators ∈ {100, 200, 300} |
max_depth ∈ {3, 5, 7} | |
learning_rate ∈ {0.05, 0.1, 0.2} |
Prévention du data leakage avec GroupKFold
Un split aléatoire placerait différents cycles du même moteur dans l’entraînement (train) et la validation. GroupKFold partitionne par moteur, garantissant que chaque fold contient des moteurs absents de l’entraînement (train).
6- Résultats
Chaque modèle est encapsulé dans un sklearn Pipeline (scaler → modèle). Le tracking des expériences avec MLflow permet de comparer directement tous les runs dans l’interface MLflow UI.
Métriques (RMSE, MAE, R², NASA Score)
Métriques de régression standard pour la sélection de modèles : $$ \mathbf{RMSE} = \sqrt{\frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2} \qquad \mathbf{MAE} = \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{y}_i| \qquad \mathbf{R^2} = 1 - \frac{\sum_{i=1}^{n} (y_i - \hat{y}_i)^2}{\sum_{i=1}^{n} (y_i - \bar{y})^2} $$
En complément, la fonction de score asymétrique de la NASA est utilisée pour la validation opérationnelle. Pour chaque moteur :
$$s_i = \begin{cases} e^{-d_i/13} - 1 & \text{si } d_i < 0 \text{ (prédiction en avance)} \\ e^{d_i/10} - 1 & \text{si } d_i \geq 0 \text{ (prédiction en retard)} \end{cases}$$où $d_i = \hat{y}_i - y_i$ est l’erreur de prédiction. Le score total est $S = \sum_i s_i$. Plus un score est faible, meilleur il est. Une défaillance non détectée est bien plus coûteuse qu’une intervention préventive inutile.
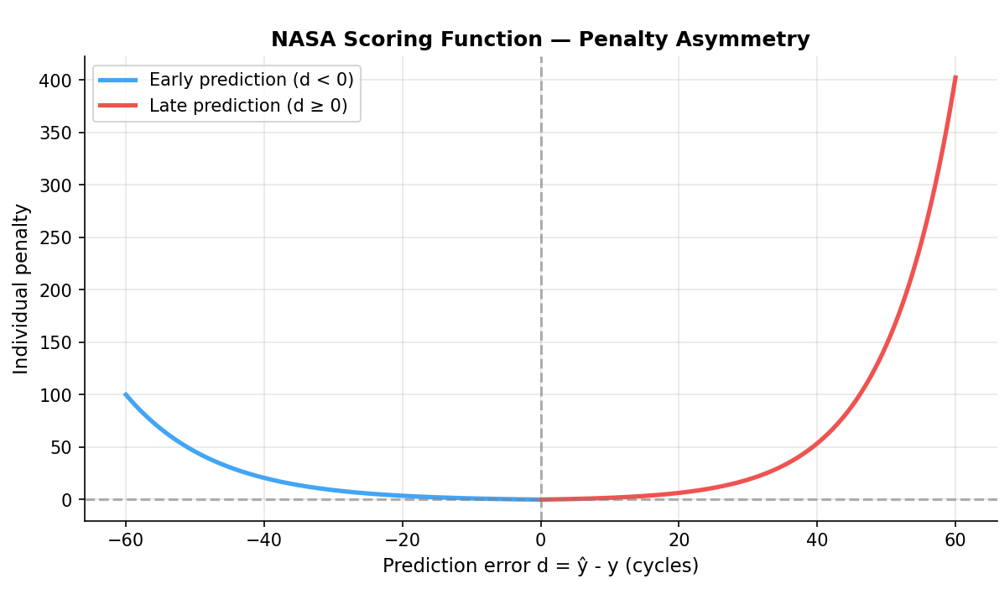
Comparaison des modèles
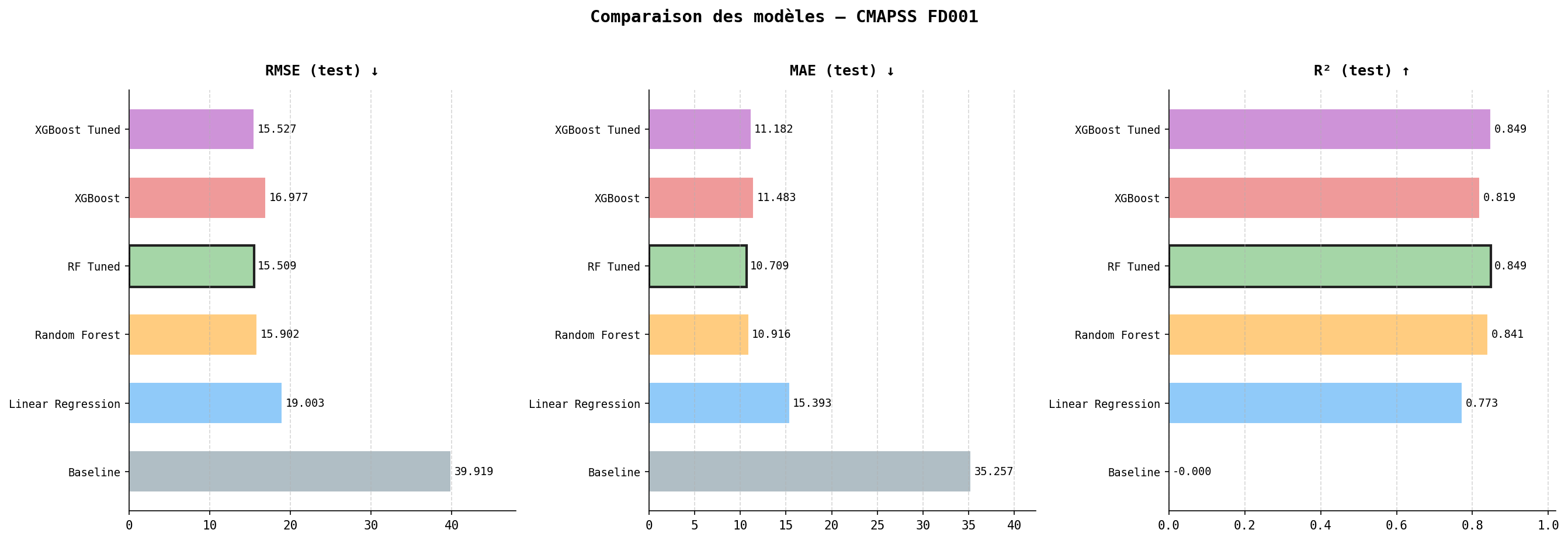
| Modèle | RMSE (test) | MAE (test) | R² (test) |
|---|---|---|---|
| Baseline | 39.92 | 35.26 | 0.000 |
| Linear Regression | 19.00 | 15.39 | 0.773 |
| Random Forest | 15.90 | 10.92 | 0.841 |
| RF Tuned | 15.51 | 10.71 | 0.849 |
| XGBoost | 16.98 | 11.48 | 0.819 |
| XGBoost Tuned | 15.53 | 11.18 | 0.849 |
Le tuning réduit drastiquement l’écart train/test pour RF et XGBoost, confirmant que les modèles vanilla étaient en overfitting. RF Tuned et XGBoost Tuned atteignent des performances quasi-identiques. Le Random Forest Tuned est retenu comme modèle final pour sa robustesse et son interprétabilité.
Benchmark NASA
Le modèle final est ré-entraîné sur l’intégralité du jeu d’entraînement, puis évalué sur le fichier de test officiel de la NASA — un jeu complètement isolé, jamais vu pendant le développement.
| Métrique | Valeur |
|---|---|
| RMSE | 17.34 cycles |
| MAE | 12.10 cycles |
| R² | 0.806 |
| NASA Score | 902.7 |
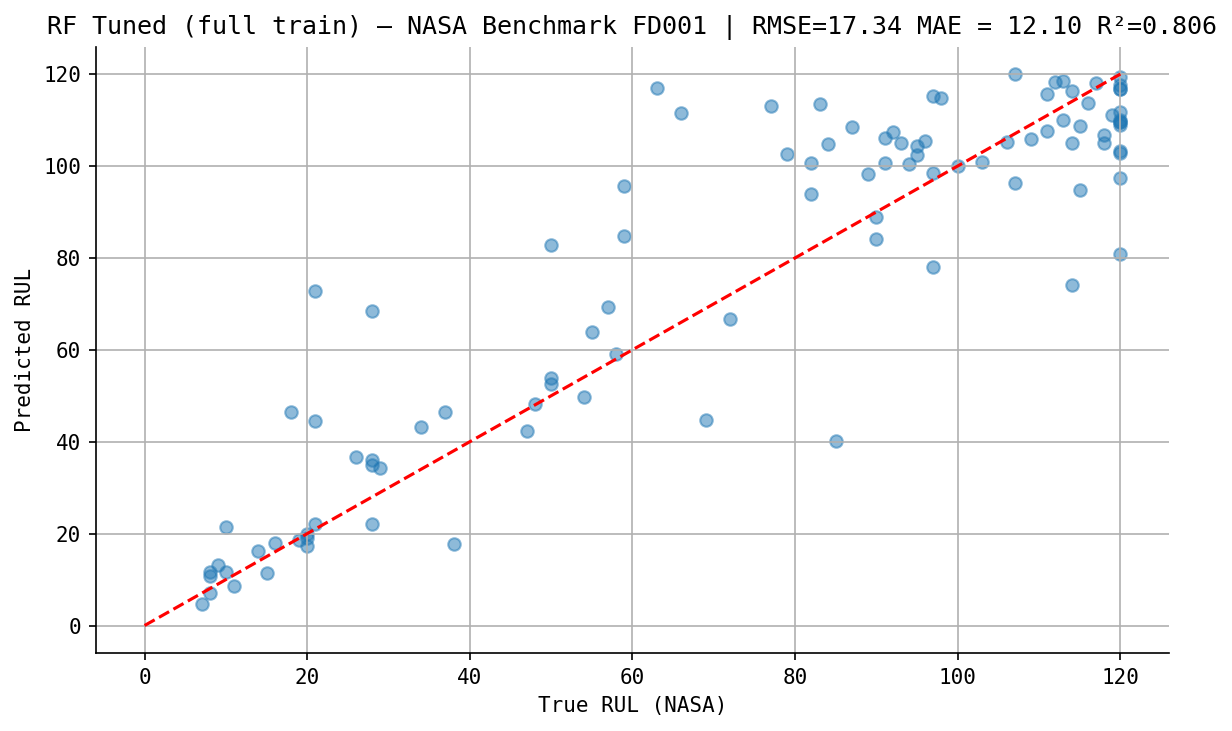
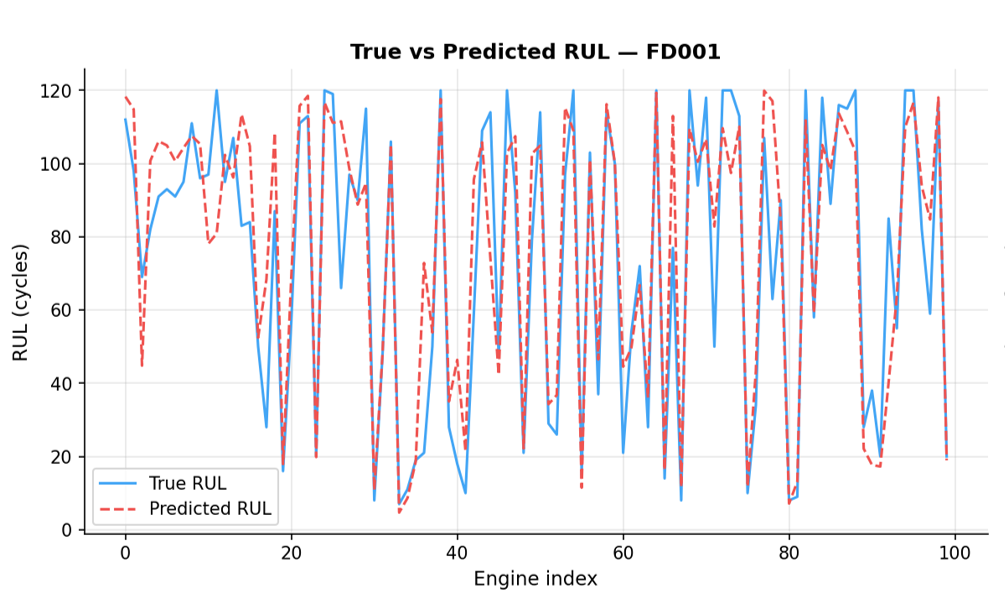
Un score NASA de 902 est un résultat encourageant, plaçant le modèle parmi les meilleures approches utilisant du Machine Learning classique sur FD001 (d’après les résultats de la compétition PHM 2008). Ce résultat est néanmoins à nuancer : FD001 est le dataset le plus simple de CMAPSS.
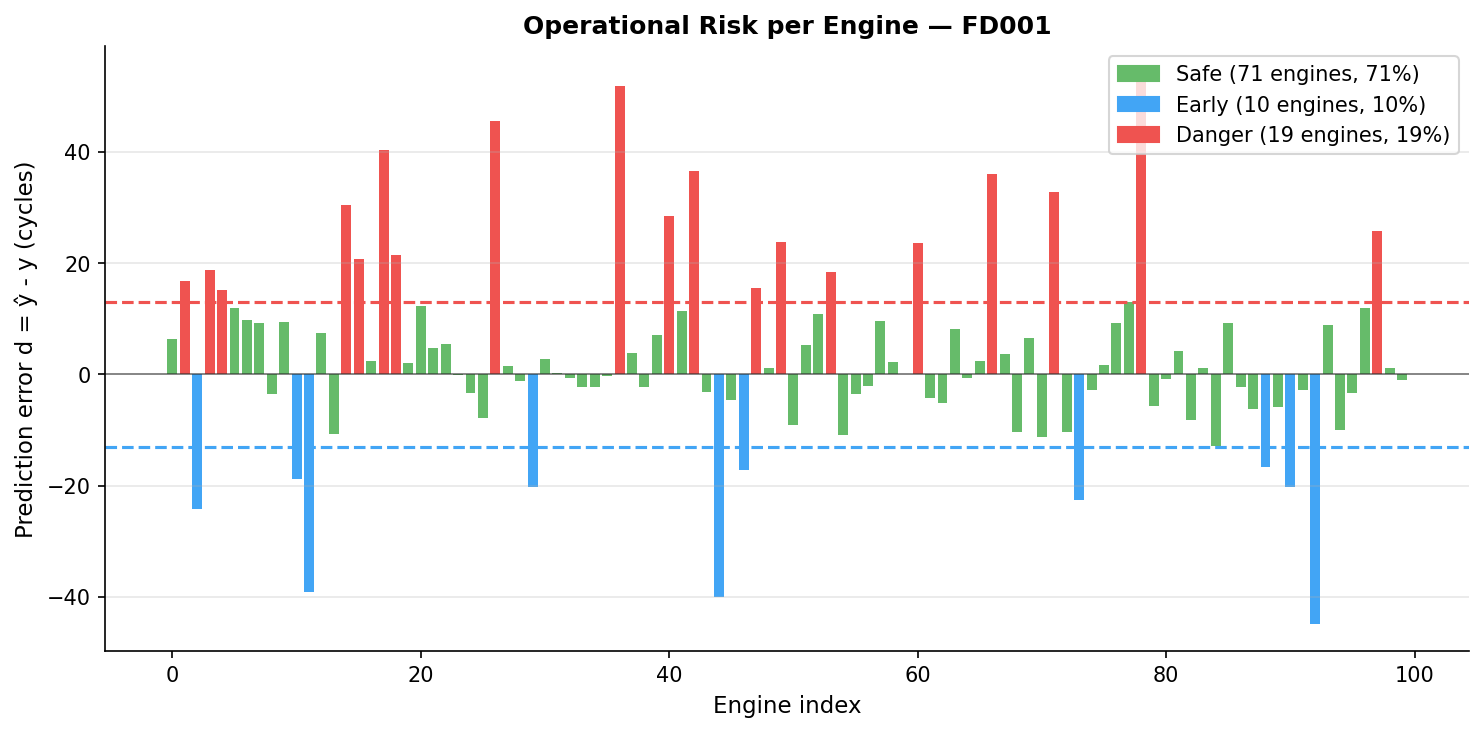
Analyse de risque opérationnel
En contexte réel, la maintenance est déclenchée lorsque le RUL prédit passe sous un seuil critique, fixé par l’opérateur. En aéronautique, ce seuil doit être conservateur compte tenu du coût important d’une défaillance en vol.
Pour traduire la performance du modèle en valeur opérationnelle, les prédictions sont classées en trois zones à partir d’un seuil de ±13 cycles (dérivé du paramètre d’échelle de la fonction NASA) :
| Zone | Condition | Conséquence opérationnelle |
|---|---|---|
| Sûre | $abs(d) \leq 13$ cycles | Maintenance planifiée correctement |
| Anticipée | $d < -13$ cycles | Intervention préventive inutile |
| Danger | $d > 13$ cycles | Risque de panne avant l’intervention |
7- Conclusion & Perspectives
Interprétation physique
T50 (température en sortie de turbine basse pression) est la feature la plus prédictive du RUL — ce qui est cohérent avec le mode de défaillance unique de FD001. Positionné en bout de chaîne, T50 intègre naturellement la dégradation de tous les composants en amont, ce qui en fait l’indicateur le plus synthétique de l’état du moteur.
Le recours à une moyenne mobile sur 5 cycles est physiquement pertinent : la dégradation mécanique est un processus lent et cumulatif, dont la signature est mieux capturée sur plusieurs cycles consécutifs qu’à partir d’une mesure instantanée.
Limites et prochaines étapes
FD001 est le dataset le plus simple de CMAPSS (condition unique, mode de défaillance unique). Étendre le modèle à FD002–FD004 (conditions multiples, modes de défaillance multiples) se rapprocherait davantage de la complexité réelle en industrie.
Le clipping à 120 cycles est une hypothèse de modélisation. En production, une approche en deux étapes pourrait d’abord classifier si le moteur est en phase de dégradation (RUL < 120), puis prédire le RUL uniquement dans ce cas.
Les architectures LSTM et Transformer surpassent les approches ML classiques sur ce benchmark en modélisant explicitement les dépendances temporelles sur l’ensemble du cycle de vie, c’est la prochaine piste à investiguer.
Python · pandas · numpy · scikit-learn · sklearn Pipeline · XGBoost · MLFlow · matplotlib · seaborn · joblib