
1- Vue d’ensemble
Note : Cette page est une note personnelle des concepts et architectures des modèles image-to-image explorés pendant mon passage à la Direction Générale de la Gendarmerie Nationale, illustrée par une petite application sur le dataset public CUHK de croquis de visages.
Génération de photos à partir de portraits-robots

2- Contexte & Motivation
Problématique
Les portraits-robots sont l’outil principal des enquêteurs lorsqu’aucune photographie du suspect n’est disponible. Produits à partir des descriptions des témoins, ce sont des croquis qui capturent la géométrie du visage mais perdent toute information sur la texture, la couleur, la peau, l’éclairage et le réalisme photographique. Le défi est de générer une image photoréaliste à partir de toutes ces informations manquantes de manière à la fois :
- Structurellement fidèle : le visage généré doit correspondre à la géométrie du croquis
- Photoréaliste : il doit ressembler à une vraie photographie
- Généralisable : il doit fonctionner sur des croquis jamais vus lors de l’entraînement
Il s’agit d’un problème d’image-to-image translation : le modèle doit apprendre une correspondance complexe d’un domaine visuel (croquis) vers un autre (photographies), sans supervision intermédiaire sur ce que devrait être la texture manquante.
Objectif de cette page
Explorer les algorithmes de génération de portraits à partir de croquis, en progressant d’un autoencoder de base vers un GAN conditionnel complet (Pix2Pix).
3- Concepts fondamentaux
Réseau de neurones convolutif (CNN)
Pour les images, les couches convolutionnelles appliquent un petit filtre qui glisse sur l’image et détecte des motifs locaux (contours, puis formes, puis features de haut niveau). C’est bien plus efficace que de connecter chaque pixel à chaque neurone.
Encoder
Un encoder est un CNN qui sous-échantillonne progressivement l’image, la comprimant en un vecteur bottleneck compact. La résolution spatiale diminue tandis que le nombre de features abstraites augmente.
Decoder
C’est le miroir de l’encoder. Il prend le bottleneck compressé et le sur-échantillonne progressivement jusqu’à la résolution d’origine via des convolutions transposées.
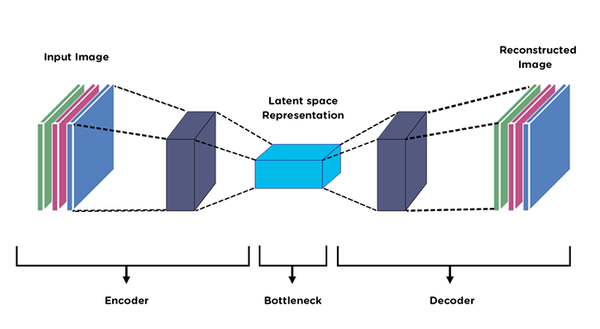
Autoencoder = Encoder + Decoder
Pour l’image-to-image, on fournit un croquis en entrée et on entraîne le decoder à produire une photo. Le réseau apprend à traduire les domaines via le bottleneck. Cependant, les détails spatiaux fins (forme exacte des yeux, positions des cheveux) sont perdus à la compression et difficiles à récupérer. C’est la limite fondamentale de l’autoencoder pur.
U-Net
Le U-Net (Ronneberger et al., 2015) ajoute des raccourcis directs qui copient les feature maps de chaque couche de l’encoder vers la couche correspondante du decoder. Celui-ci peut alors utiliser à la fois le contexte sémantique de haut niveau (depuis le bottleneck) et les détails spatiaux de bas niveau (depuis les skip connections), produisant des sorties plus nettes et plus fidèles.
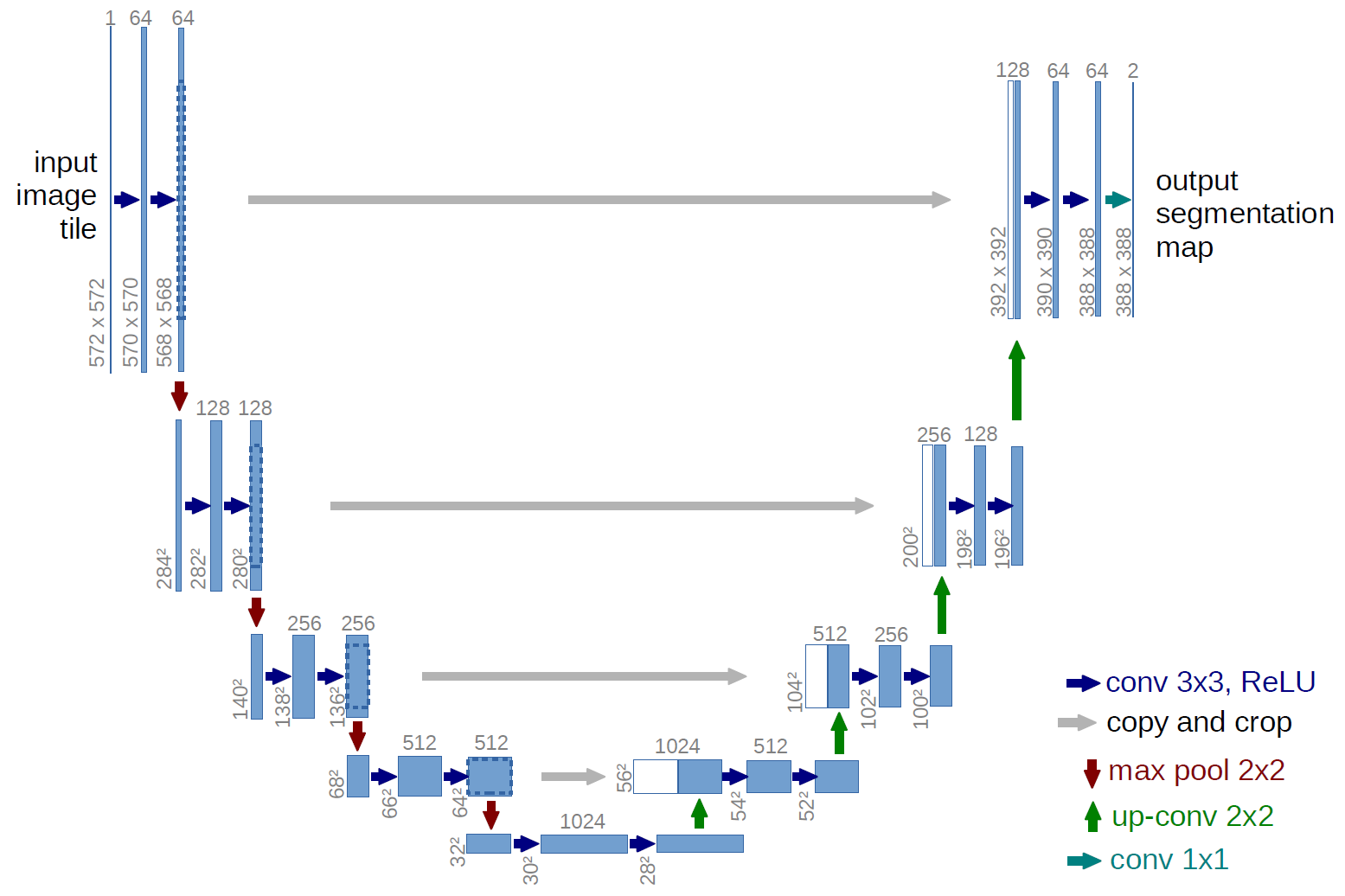
Les skip connections permettent au decoder de recevoir à la fois la représentation sémantique abstraite du bottleneck et les informations spatiales précises préservées depuis les premières couches de l’encoder.
GAN (Generative Adversarial Network)
Même avec un U-Net, entraîner avec une loss MAE tend à produire des sorties floues. En effet, la loss MAE fait la moyenne de toutes les sorties plausibles : si le réseau est incertain entre deux textures plausibles, il les moyenne, produisant du flou. Un GAN résout ce problème en ajoutant un second réseau, le discriminateur, entraîné en opposition contre le générateur :
$$\mathcal{L}_{ ext{GAN}} = \mathbb{E}[\log D(x, y)] + \mathbb{E}[\log(1 - D(x, G(x)))]$$
où $x$ est le croquis (condition), $y$ est la vraie photo, $G(x)$ est la photo générée. G est forcé à produire des détails nets et réalistes, car tout flou est immédiatement détecté par D comme fausse image.
Pix2Pix
Pix2Pix (Isola et al., 2017) combine U-Net + PatchGAN pour la transformation d’image supervisée. Le discriminateur PatchGAN classe des patches de 70×70 pixels comme réels ou faux plutôt que l’image entière, forçant ainsi un réalisme de texture locale partout, pas seulement une plausibilité globale.
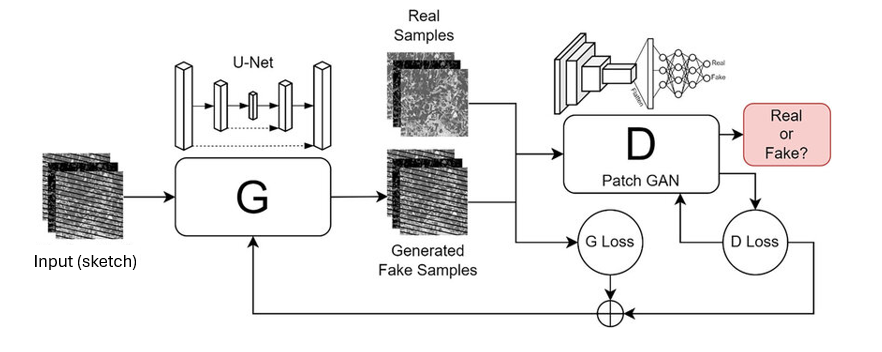
MAE permet une sortie proche de la vraie photo, tandis que le réseau GAN force le réalisme local.
4- Exemple d’application sur le dataset CUHK
CUHK Face Sketch Database
C’est le benchmark académique de référence pour la synthèse portrait-croquis/photo. Il contient des paires croquis/photo réalisées par des étudiants en art à partir de vraies photographies.
| Split | Paires |
|---|---|
| Entraînement | 550 |
| Test | 56 |
Le dataset est très petit au regard des standards du deep learning. Une augmentation de données est appliquée (flips et rotations, appliqués symétriquement aux paires croquis/photo pour conserver la cohérence).
Résultats
Trois exemples du jeu de test, portrait-croquis → vraie photo → prédiction du modèle :

Métriques d’évaluation : SSIM et PSNR
L’évaluation visuelle est la première approche naturelle pour ce type de tâche, mais elle ne permet pas de comparer des modèles de manière reproductible. Deux métriques sont standard pour la qualité d’image générée.
PSNR (Peak Signal-to-Noise Ratio) mesure le rapport entre la valeur maximale possible d’un pixel et la puissance du bruit de reconstruction, exprimé en décibels :
$$\text{PSNR} = 10 \cdot \log_{10}\left(\frac{\text{MAX}^2}{\text{MSE}}\right) \qquad \text{avec} \quad \text{MSE} = \frac{1}{N}\sum_{i=1}^{N}(y_i - \hat{y}_i)^2$$
où MAX est la valeur maximale d’un pixel (255 pour une image 8 bits), et MSE l’erreur quadratique moyenne entre l’image réelle $y$ et l’image générée $\hat{y}$. Plus le PSNR est élevé, plus la reconstruction est fidèle. Un PSNR > 20 dB est généralement considéré comme acceptable pour la synthèse de visages.
SSIM (Structural Similarity Index) évalue la similarité perceptuelle entre deux images en combinant trois composantes : luminance, contraste et structure :
$$\text{SSIM}(y, \hat{y}) = \frac{(2\mu_y\mu_{\hat{y}} + c_1)(2\sigma_{y\hat{y}} + c_2)}{(\mu_y^2 + \mu_{\hat{y}}^2 + c_1)(\sigma_y^2 + \sigma_{\hat{y}}^2 + c_2)}$$
où $\mu$ désigne la moyenne locale, $\sigma^2$ la variance locale, $\sigma_{y\hat{y}}$ la covariance, et $c_1, c_2$ des constantes de stabilisation. SSIM prend ses valeurs dans $[-1, 1]$, une valeur de 1 indiquant une similarité parfaite. Contrairement au PSNR, il est conçu pour mieux refléter la perception humaine de la qualité d’image.
Dans l’exemple ci-dessus, SSIM ≈ 0,64 et PSNR ≈ 17,3 dB, limité par les capacités de mon ordinateur. Pour Pix2Pix appliqué au même dataset, les valeurs de référence rapportées sont SSIM ≈ 0,70 et PSNR ≈ 18,4 dB en configuration baseline, améliorées à SSIM ≈ 0,81 et PSNR ≈ 23,0 dB avec un prétraitement d’inversion gamma des croquis. Ces valeurs sont cohérentes avec les miennes, les résultats dépendant de la durée d’entraînement, de l’augmentation de données/quantité de données initiales et du matériel disponible.
Python · TensorFlow / Keras · NumPy · Matplotlib · PIL