
Voir le rapport complet (PDF) →
1- Vue d’ensemble
Étude analysant les déplacements de +2,4M d’utilisateurs californiens pour orienter la politique de réduction des GES de la Californie à horizon 2030 - machine learning, analyse géospatiale big data et data science.
2- Contexte & Motivation
Problématique
La Californie s’est engagée à réduire ses émissions de gaz à effet de serre de 40% sous les niveaux de 1990 d’ici 2030. Le secteur des transports est le principal contributeur à ces émissions, et les Vehicle Miles Traveled (VMT) (le kilométrage parcouru en voiture) constituent un levier central. La pandémie de COVID-19 a créé une expérience grandeur nature sans précédent : une perturbation soudaine et à l’échelle de l’État qui a révélé quels comportements de déplacement sont habituels (et réversibles) et lesquels sont structurels (et permanents).
Le California Air Resources Board (CARB), en partenariat avec l’Université de Californie à Berkeley et le Lawrence Berkeley National Laboratory, a commandité cette étude pour quantifier ces changements et les traduire en recommandations politiques concrètes.
Défi technique
Comprendre la mobilité à cette échelle requiert de résoudre simultanément trois problèmes distincts : inférer le mode de transport (voiture vs marche) depuis des données GPS bruts sans label, détecter les déménagements résidentiels, et mesurer les changements structurels des flux de déplacement domicile-travail sur ~8 000 secteurs de recensement sur quatre ans. Chacun nécessite une approche algorithmique différente: non supervisée, semi-supervisée et par analyse de graphes respectivement.
Objectif du projet
Mesurer l’impact du COVID-19 sur les VMT, les déplacements domicile-travail et les déménagements résidentiels, à partir de quatre années de données LBS anonymisées, puis en déduire des stratégies de réduction des VMT ciblées par région et groupe démographique pour alimenter la feuille de route climatique 2030 du CARB.
3- Dataset
Données Location-Based Service (LBS) fournies par Spectus : pings GPS de téléphones mobiles anonymisés collectés en Californie de 2019 à 2022.
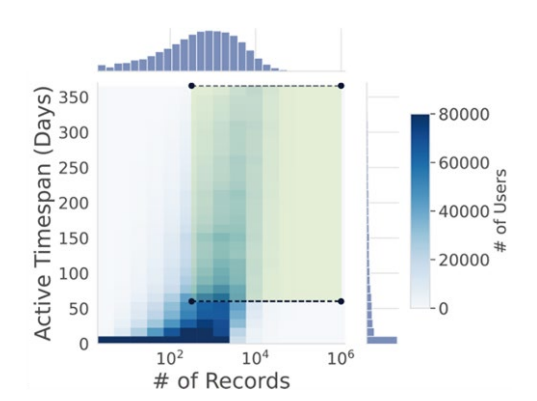
Résolution spatiale : census block group (~600–3 000 personnes). Filtres qualité appliqués pour ne conserver que les utilisateurs avec une couverture suffisante : >316 pings, >60 jours actifs.
Détection du domicile et du lieu de travail par méthode heuristique sur la localisation la plus fréquentée pendant la plage horaire appropriée :
home = most_freq_location(user, time_range="7pm-7am", min_visits=10)
work = most_freq_location(user, time_range="7am-7pm", weekdays_only=True, min_visits=10)
Dataset final :
| Année | Utilisateurs totaux | Haute qualité | Domicile + travail détectés |
|---|---|---|---|
| 2019 | 9,4M | 3 482 574 | 861 167 |
| 2020 | 5,9M | 2 396 990 | 431 190 |
| 2021 | 5,2M | 2 036 110 | 465 311 |
| 2022 | 5,6M | 2 582 405 | 702 847 |
4- Méthodologie
Algorithme 1 - Détection de mode par GMM
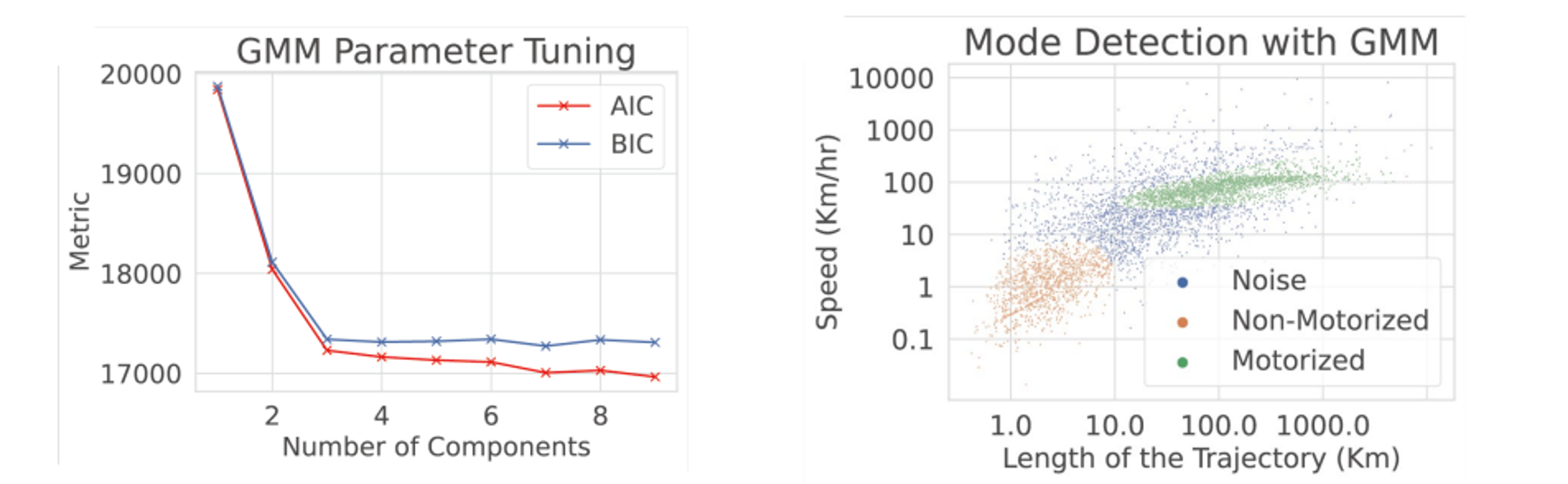
Aucune donnée de trajet labelisée n’est disponible. Il est donc impossible d’entraîner un algorithme de classification supervisé sans connaître le moyen de transport réel de chaque trajet. On doit inférer le mode de transport uniquement à partir de la structure des données. Deux signaux suffisent à séparer les trajets motorisés des trajets non-motorisés : la vitesse maximale atteinte et la distance parcourue. Un trajet en voiture et un trajet à pied occupent des régions très différentes dans l’espace (vitesse, distance). Ainsi, même sans labels, ces clusters devraient être visibles.
Un Gaussian Mixture Model (GMM) suppose que les données ont été générées par un mélange de $k$ distributions gaussiennes, chacune représentant un cluster naturel. Plutôt qu’assigner chaque point à un unique cluster comme le ferait le K-Means, un GMM produit une probabilité d’appartenance à chaque cluster. Cela importe ici car certains trajets sont ambigus (une voiture roulant lentement ressemble à un vélo rapide).
La probabilité d’observer un vecteur de features $X$ s’écrit :
$$\text{GMM}(X) = \sum_{k=1}^{3} \pi_k ,\mathcal{N}(X \mid \mu_k, \Sigma_k)$$
où $\pi_k$ est le poids du composant $k$, $\mu_k$ sa moyenne et $\Sigma_k$ sa covariance. Le modèle est ajusté par Expectation-Maximization : on alterne entre l’assignation de probabilités à chaque point étant donné les paramètres courants, et la mise à jour des paramètres étant donné les assignations courantes.
On utilise la méthode du coude AIC/BIC pour déterminer $k$. Les deux critères mesurent la qualité d’ajustement pénalisée par la complexité :
$$\text{AIC} = 2p - 2\ln(\hat{L}) \qquad \text{BIC} = p\ln(n) - 2\ln(\hat{L})$$
où $p$ est le nombre de paramètres, $n$ le nombre d’observations et $\hat{L}$ la vraisemblance maximisée. Tracer AIC/BIC en fonction de $k$ produit un “coude”: c’est le point à partir duquel ajouter des clusters supplémentaires n’améliore plus significativement le score. Ce coude tombe ici à $k=3$, confirmant trois clusters naturels.
Rayon de giration
Le rayon de giration $r_g$ est une valeur résumant la dispersion spatiale des déplacements d’un utilisateur. C’est le rayon typique de sa bulle d’activité quotidienne. Il s’inspire de la physique, où le rayon de giration d’une distribution de masses mesure leur étalement autour de leur centre de masse.
$$r_g(u) = \sqrt{\frac{1}{n_u} \sum_{i=1}^{n_u} \text{dist}\left(r_i(u),\ r_{cm}(u)\right)^2}$$
où $r_i(u)$ sont tous les lieux visités et $r_{cm}(u)$ leur centroïde pondéré. C’est la distance quadratique moyenne depuis le domicile. Un $r_g$ élevé signale des déplacements longue distance dépendants de la voiture, typiques des résidents ruraux. Un $r_g$ faible indique une mobilité réduite et piétonne, typique des résidents urbains.
En suivant $r_g$ avant et après le confinement, on quantifie non seulement si les personnes se sont moins déplacées, mais si elles ont parcouru des distances plus courtes, une distinction qui importe pour la politique de réduction des VMT.
Algorithme 2 - Détection de déménagement par KMeans-SVM
Le défi est de détecter les déménagements intra-étatiques (>=5 miles) depuis des patterns GPS nocturnes, sans aucune donnée de déménagement labelisée. Distinguer un vrai déménagement de patterns bruités (vacances, déplacement professionnel, séjour temporaire) nécessite une frontière de décision robuste.
K-Means (non supervisé) partitionne les localisations nocturnes en 2 clusters en minimisant la variance intra-cluster :
$$\underset{C_1, C_2}{\arg\min} \sum_{k=1}^{2} \sum_{x_i \in C_k} | x_i - \mu_k |^2$$
Appliqué à (latitude, longitude, jours depuis le 1er janvier), les deux clusters représentent naturellement “les nuits avant le déménagement” et “les nuits après”, fournissant des pseudo-labels pour l’étape suivante.
Le Support Vector Machine (SVM) (supervisé) trouve l’hyperplan qui maximise la marge entre les deux classes. Avec $C = 0{,}01$, l’algorithme de classification préfère commettre quelques erreurs sur des nuits ambiguës plutôt que de tracer une frontière trop serrée qui overfitterait le bruit géographique, évitant ainsi de confondre une semaine de vacances avec un déménagement.
La date du déménagement est estimée à la frontière entre les deux clusters :
$$\text{MoveDate} = \min\bigl(\max(C_{\text{avant}}),\ \max(C_{\text{après}})\bigr)$$
Algorithme 3 — Détection de communautés de Louvain
Du ping GPS au réseau : plutôt qu’analyser des trajets individuels, on construit un graphe de la structure agrégée des déplacements domicile-travail en Californie. Chaque secteur de recensement est un nœud, une arête relie deux secteurs si des utilisateurs y font la navette, pondérée par leur nombre. Cela donne un graphe dirigé pondéré de ~8 000 nœuds et jusqu’à 145 000 arêtes.
L’algorithme de Louvain identifie les groupes de nœuds plus densément connectés en interne qu’au reste du réseau. Ce sontles bassins naturels de déplacement domicile-travail. Il maximise la modularité $Q$, qui mesure l’excès de flux intra-communautaire par rapport à ce qu’on attendrait par hasard :
$$Q = \frac{1}{2m} \sum_{i,j} \left[ A_{ij} - \frac{k_i k_j}{2m} \right] \delta(c_i, c_j)$$
où $A_{ij}$ est le poids de l’arête entre les secteurs $i$ et $j$, $k_i$ le poids total des arêtes touchant le nœud $i$, $m$ la somme de tous les poids d’arêtes, et $\delta(c_i, c_j) = 1$ si $i$ et $j$ appartiennent à la même communauté.
Un $Q$ élevé signale un isolement régional fort, les navetteurs restent dans leur bassin de déplacement. Un $Q$ faible indique un réseau intégré où les personnes traversent librement les frontières régionales. Suivre $Q$ et le nombre de communautés d’une année sur l’autre révèle si le COVID a fragmenté durablement la géographie des déplacements domicile-travail en Californie.
5- Résultats
Réduction des VMT & disparités régionales
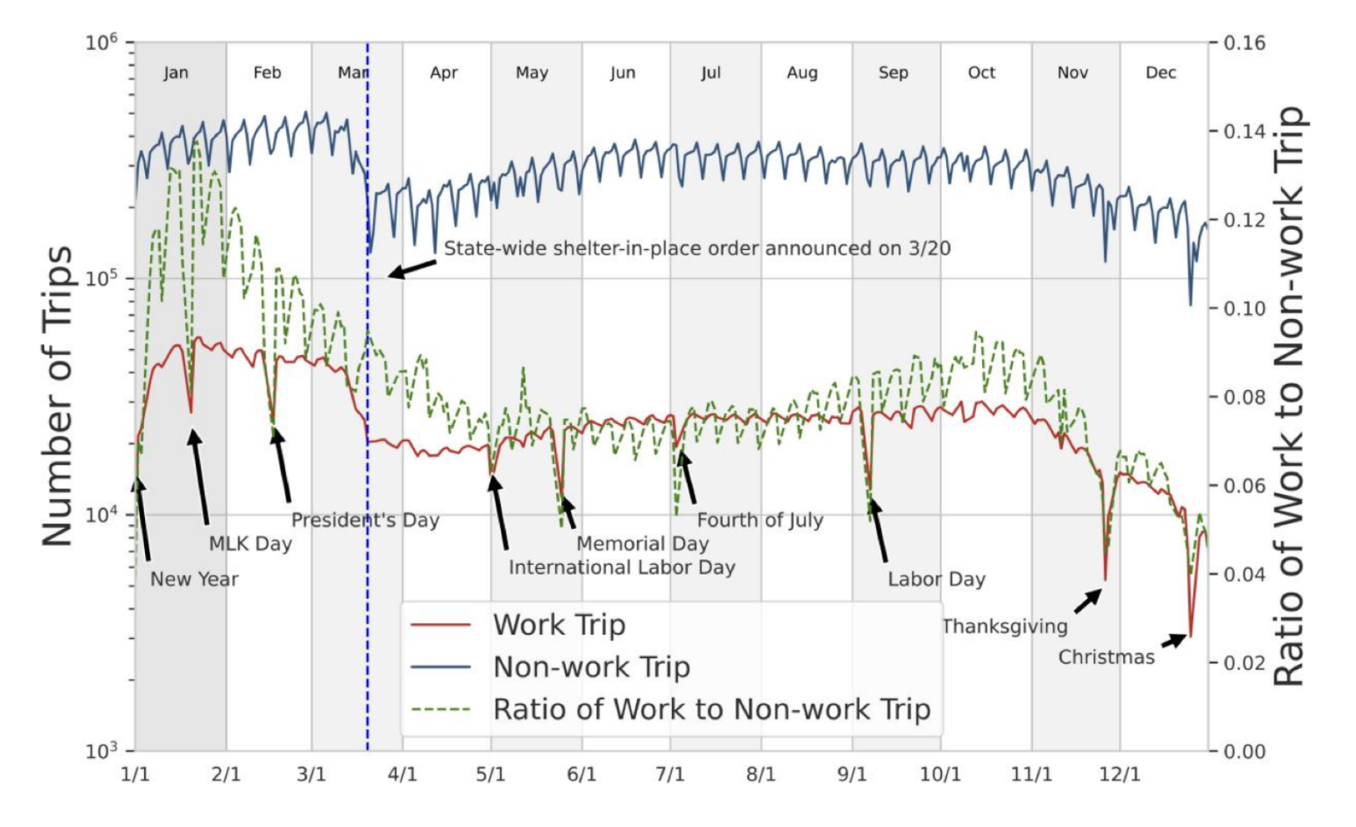
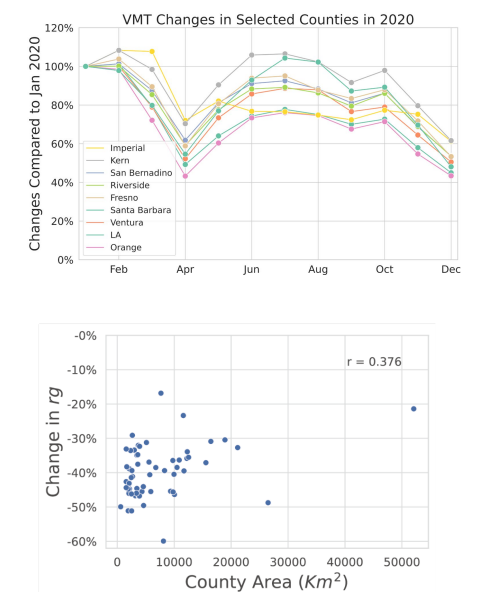
Les zones urbaines (LA, Orange, Santa Barbara) ont enregistré des réductions des VMT de 38–55% en avril 2020, les zones rurales (Imperial, Kern) seulement 20–30%. L’écart de 20 points reflète une dépendance à la voiture fondamentalement différente : les résidents urbains pouvaient substituer les trajets en voiture par la marche ou le télétravail, tandis que les résidents ruraux pour la majorité ne le pouvaient pas. Une corrélation positive (r=0,376) entre la superficie de la zone et la persistance des VMT confirme que cette dépendance est structurelle et non comportementale.
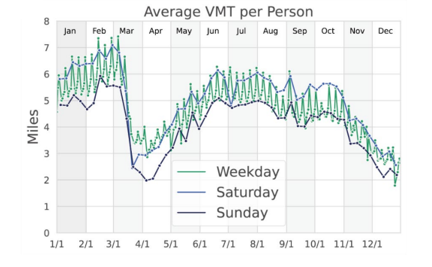
Le COVID-19 n’a pas modifié la variation intra-hebdomadaire des VMT, les patterns hebdomadaires étant préservés. Au début du confinement, on observe une réduction plus marquée des VMT le week-end par rapport aux jours de semaine.
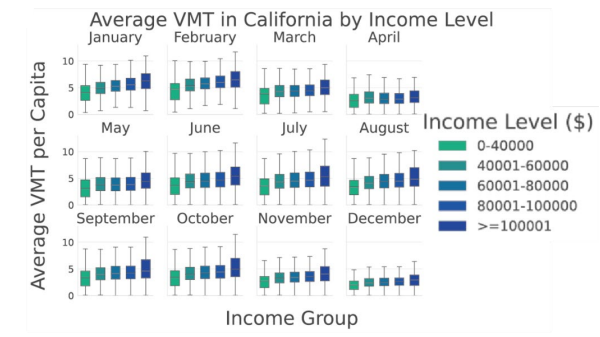
Aucune différence notable entre classes socio-professionnelles dans la réduction initiale des VMT. Les CSP+ ont en revanche connu un rebond plus rapide, probablement en raison d’une plus grande flexibilité et faisabilité du télétravail.
Déménagements résidentiels
Un pic brutal de déménagements s’est produit dans la fenêtre de 15 jours entre la déclaration d’état d’urgence (4 mars) et l’ordre de confinement (19 mars 2020).
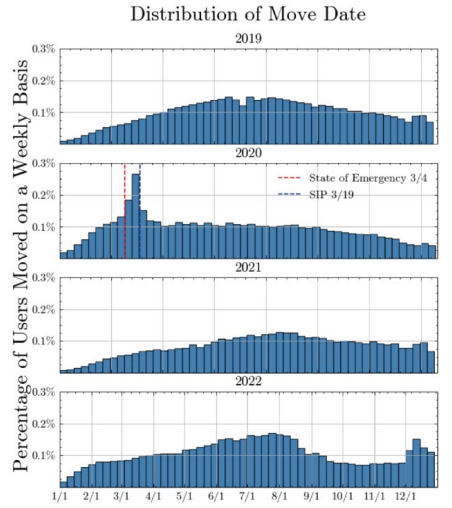
La distribution des distances pendant cette fenêtre de crise était bimodale : un mode à ~80 km (reshuffling local au sein des zones métropolitaines) et un mode à ~550 km (inter-régional). On observe davantage de déménagements longue distance dans cette période de deux semaines, et les grandes zones urbaines enregistrent un exode fort. L’immigration et l’émigration dans les villes de la Central Valley comme Bakersfield et Fresno restent stables.
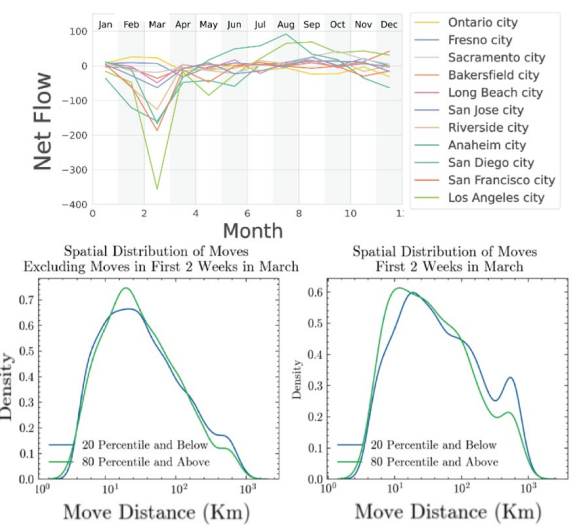
Motif de déplacement & Fragmentation du réseau domicile-travail
Les déplacements hors-travail (shopping, loisirs) ont retrouvé leur niveau de base à partir de 2022. Toutefois, les trajets domicile-travail n’ont jamais retrouvé leur niveau pré-pandémique. Le télétravail et le travail hybride ont restructuré non seulement le lieu de travail des personnes, mais également la demande plus globale de déplacement quotidien en Californie.
| Année | Arêtes | Communautés | Modularité |
|---|---|---|---|
| 2019 | 145 838 | 6 | 0,628 |
| 2020 | 89 382 | 8 | 0,653 |
| 2021 | 73 401 | 8 | 0,648 |
| 2022 | 111 652 | 8 | 0,666 |
Le réseau a perdu 38,7% de ses arêtes en 2020. Deux nouvelles communautés isolées ont émergé dans des régions éloignées (El Centro, Sierras orientales). La modularité est restée élevée jusqu’en 2022, et même après une récupération partielle des arêtes le réseau n’a jamais retrouvé sa structure d’avant-pandémie. Les grands centres urbains (SF, LA, San Diego) continuent d’exercer une influence gravitationnelle dominante sur leurs régions environnantes.
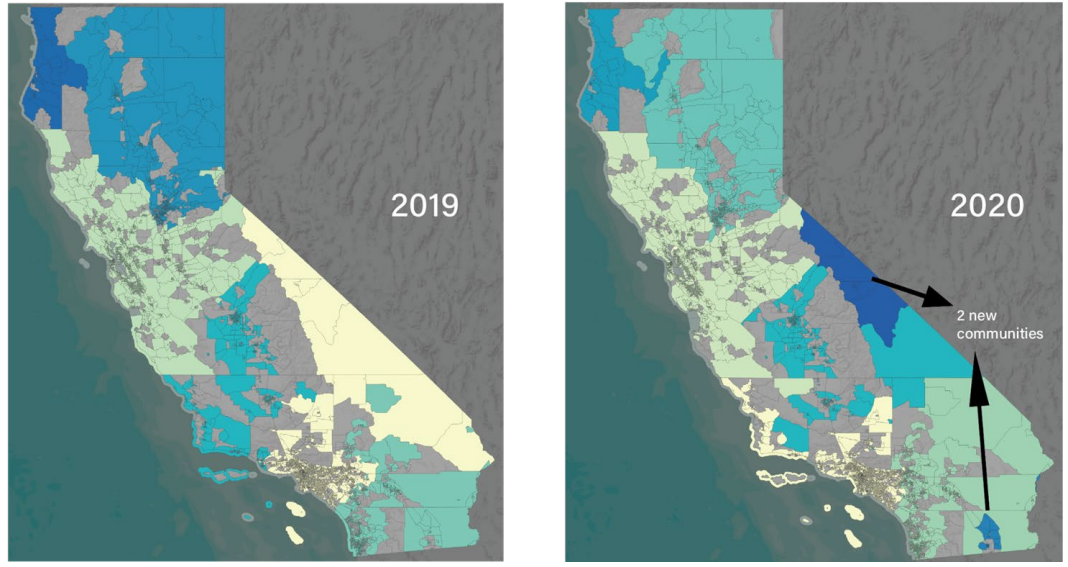
6- Impact & Recommandations politiques
Résultats validés : Les données LBS ont été confirmées comme alternative viable et économique aux enquêtes de déplacement coûteuses. Des algorithmes open-source réutilisables pour la détection de mode et l’analyse des déménagements sans données labelisées ont été développés, et la feuille de route 2030 du CARB a été alimentée par des objectifs de réduction des VMT. Les résultats se traduisent par quatre leviers politiques concrets :
Zones urbaines : Il faut capitaliser sur la réduction structurelle de la dépendance automobile post-COVID : réformes autour des transports en commun, réduction des minimums de stationnement et développement de densité en banlieue permettraient de consolider ces gains plutôt que de laisser l’usage de la voiture reprendre.
Zones rurales : La dépendance automobile a persisté précisément là où les alternatives sont absentes. L’infrastructure de recharge pour véhicules électriques et les voies de covoiturage répondent à la question des émissions sans exiger de changement comportemental.
Télétravail : Il est désormais structurellement ancré dans le marché du travail californien. La politique d’utilisation des sols devrait s’adapter en encourageant le développement résidentiel près des pôles d’emploi en banlieue et en réduisant les VMT liés aux trajets domicile-travail.
Micromobilité : C’est la seule catégorie d’intervention ayant montré un effet mesurable sur le report modal. La politique devrait prioriser la densité de déploiement rapide plutôt que l’étendue géographique.
Python · pandas · numpy · scikit-learn · networkx · geopandas · matplotlib